



In der heutigen schnelllebigen Geschäftswelt, wo Unternehmen in atemberaubender Geschwindigkeit wachsen und sich entwickeln, steht man oft vor der Herausforderung, Schritt zu halten. Mit jedem neuen Projekt, jeder Expansion und jeder Innovation sammeln sich Berge von Wissen an, die es zu verwalten gilt. Doch mit zunehmender Größe eines Unternehmens wächst auch die Komplexität seiner Informationslandschaft. Was einst in den Köpfen weniger Schlüsselpersonen gespeichert war, verteilt sich nun auf unzählige Dokumente, Wikis und Datenbanken. In dieser Umgebung wird das Wissen schnell unübersichtlich und schwer zugänglich.Diese Fragmentierung des Wissens führt zu einer alltäglichen Herausforderung: Die Suche nach spezifischen Informationen gleicht oft einer Nadel im Heuhaufen. Mitarbeiter müssen sich durch endlose Wikis lesen, lange E-Mail-Ketten durchforsten oder Kollegen und Experten befragen, in der Hoffnung, die benötigten Informationen zu finden. Dieser Prozess ist nicht nur zeitaufwendig, sondern kann auch zu Verzögerungen bei der Entscheidungsfindung und der Umsetzung von Projekten führen. In solch einem Umfeld ist es essentiell, innovative Lösungen zu finden, die den Zugriff auf und die Verwaltung von Wissen effizienter gestalten.Hier setzt die Retrieval Augmented Generation, kurz RAG, an – eine fortschrittliche Technologie, die das Potenzial hat, die Art und Weise, wie wir mit Wissen in Unternehmen umgehen, grundlegend zu verändern. RAG nutzt KI-gestützte Methoden, um relevante Informationen aus einem riesigen Pool von Daten zu extrahieren und zu generieren, wodurch die Wissenssuche nicht nur beschleunigt, sondern auch präziser wird. In diesem Blogbeitrag werden wir uns eingehend mit RAG beschäftigen, seine Funktionsweise erläutern und aufzeigen, wie es die Herausforderungen der Wissensverwaltung in wachsenden Unternehmen adressieren kann.
Das RAG-Framework
Um das Konzept von RAG und seine Anwendung in der Praxis zu verstehen, ist es wichtig, zwei grundlegende Konzepte zu erfassen: Embeddings und Vektordatenbanken. Diese bilden das Fundament, auf dem RAG aufbaut, um internes Wissen effizient zugänglich zu machen.
Embeddings
Im Kern sind Embeddings dichte Vektordarstellungen von Texten, Wörtern oder Phrasen, die es ermöglichen, die semantische Bedeutung dieser Einheiten in einem kontinuierlichen Vektorraum abzubilden. Stellen Sie sich vor, jedes Wort oder jeder Text wird durch einen Punkt in einem mehrdimensionalen Raum repräsentiert, wobei die Position dieses Punktes die Bedeutung des Wortes oder Textes widerspiegelt. Näher beieinander liegende Punkte repräsentieren dabei ähnliche Bedeutungen. Diese Darstellungsform ermöglicht es Computern, mit natürlicher Sprache in einer Weise zu arbeiten, die Nuancen und Kontext berücksichtigt.Die Erstellung von Embeddings erfolgt durch Algorithmen des maschinellen Lernens, die auf großen Textmengen trainiert werden. Diese Algorithmen lernen, Wörter oder Texte basierend auf ihrem Kontext zu interpretieren, wodurch sie in der Lage sind, ähnliche Begriffe nahe beieinander im Vektorraum anzuordnen. Ein bekanntes Beispiel für solche Algorithmen ist Word2Vec, aber es gibt viele andere, darunter auch solche, die ganze Sätze oder Dokumente in Vektoren umwandeln können, wie z.B. BERT.
Vektordatenbanken
Vektordatenbanken sind spezialisierte Datenbanksysteme, die darauf ausgelegt sind, große Mengen von Vektoren effizient zu speichern, zu durchsuchen und zu verwalten. Im Kontext von Embeddings ermöglichen sie es, die semantische Suche zu realisieren. Anstatt nach exakten Übereinstimmungen zu suchen, wie es bei traditionellen Textsuchen der Fall ist, ermöglichen Vektordatenbanken die Suche nach ähnlichen Embeddings. Das heißt, man kann nach Dokumenten, Wörtern oder Phrasen suchen, die in ihrer Bedeutung einem gegebenen Beispieltext ähnlich sind, selbst wenn die exakten Worte nicht übereinstimmen.
Umwandlung internen Wissens in Embeddings
Die Umwandlung von internem Wissen in Embeddings beginnt mit der Extraktion von Texten aus verschiedenen Quellen innerhalb eines Unternehmens – von Dokumenten, E-Mails, Wikis bis hin zu Datenbanken. Diese Texte werden dann durch die oben erwähnten Algorithmen verarbeitet, um ihre Vektorrepräsentationen zu erstellen. Dieser Prozess transformiert unstrukturierte Informationen in eine strukturierte Form, die in einer Vektordatenbank gespeichert und effizient durchsucht werden kann.Durch die Nutzung von Embeddings und Vektordatenbanken kann RAG schnell und präzise Informationen aus einem großen Pool von internem Wissen abrufen. Dies geschieht, indem Anfragen in Vektoren umgewandelt und die relevantesten Einträge in der Vektordatenbank gefunden werden, basierend auf ihrer Nähe im Vektorraum. Diese Methode ermöglicht es Unternehmen, auf eine revolutionäre Art und Weise auf ihr gesammeltes Wissen zuzugreifen, wodurch die Effizienz gesteigert und die Entscheidungsfindung beschleunigt wird.
Die RAG-Pipeline
Um Benutzeranfragen, auch Prompts genannt, effektiv mit internem Wissen zu beantworten, nutzen RAG-Systeme und ähnliche Technologien oft die Similarity Search, um relevante Informationen aus einer Vektordatenbank zu extrahieren. Dieser Prozess verbessert die Fähigkeit von Large Language Models, kurz LLM, präzise und kontextbezogene Antworten zu generieren. Hier ist eine detaillierte Beschreibung, wie dieser Prozess funktioniert:
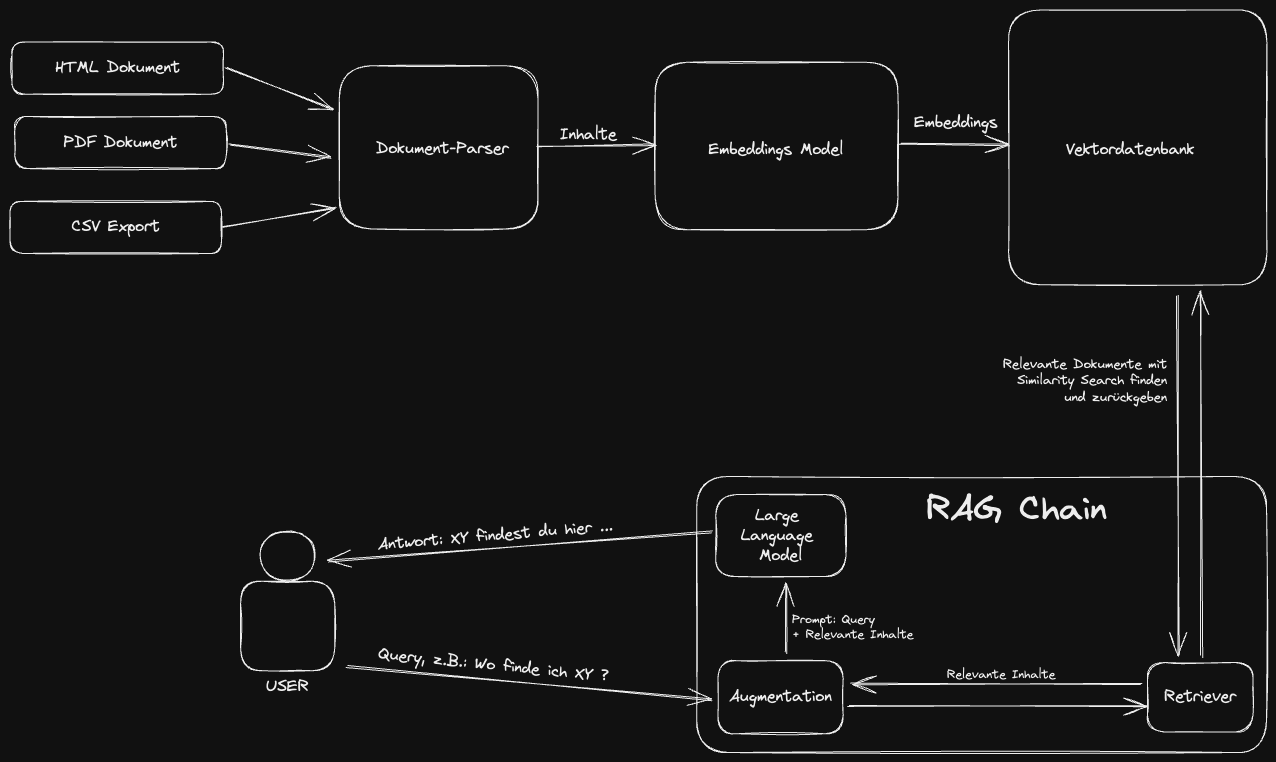
Schritt 1: Umwandlung der Benutzer Prompts in Vektoren
Zuerst wird die Benutzeranfrage in einen Vektor umgewandelt, ähnlich wie internes Wissen in Embeddings transformiert wird. Diese Umwandlung ermöglicht es, die semantische Bedeutung der Anfrage in einem hochdimensionalen Vektorraum zu repräsentieren. Hierbei kommen oft dieselben oder ähnliche Algorithmen zum Einsatz, die auch für die Erstellung der Embeddings verwendet wurden, um sicherzustellen, dass die Vektoren kompatibel sind.
Schritt 2: Durchführung der Similarity Search
Mit dem Vektor des Prompts führt das System eine Similarity Search in der Vektordatenbank durch. Ziel ist es, diejenigen Einträge (Dokumente, Fragmente, Antworten etc.) zu finden, deren Vektoren am nächsten am Vektor des Prompts liegen. Diese Nähe wird typischerweise über Metriken wie den Kosinus-Ähnlichkeitswert bestimmt. Je höher der Ähnlichkeitswert, desto relevanter ist der gefundene Eintrag für die Benutzeranfrage.
Schritt 3: Auswahl und Anreicherung des Prompts
Aus den Ergebnissen der Similarity Search wählt das System die relevantesten Informationen aus, die zur Beantwortung der Benutzeranfrage beitragen können. Diese Informationen werden dann verwendet, um die ursprüngliche Benutzeranfrage anzureichern. Diese Anreicherung kann verschiedene Formen annehmen, z.B. das Hinzufügen spezifischer Fakten, das Einbetten von Kontextinformationen oder das Anbieten von Hintergrundwissen, das direkt mit der Anfrage zusammenhängt.
Schritt 4: Generierung der Antwort durch das LLM
Das angereicherte Prompt wird anschließend an das LLM übergeben. Durch die zusätzlichen Informationen ist das LLM besser in der Lage, eine präzise und fundierte Antwort zu generieren. Es nutzt sowohl die originale Benutzeranfrage als auch die ergänzten Informationen, um eine Antwort zu erstellen, die nicht nur auf seinem trainierten Wissen basiert, sondern auch auf spezifischem, durch die Similarity Search gefundenem Wissen.
Vorteile dieser Methode
- Erhöhte Genauigkeit: Durch die Anreicherung der Prompts mit spezifischem, relevantem Wissen können LLMs präzisere Antworten liefern, die auf die spezifischen Bedürfnisse und Kontexte der Benutzer zugeschnitten sind.
- Kontextbezogene Antworten: Diese Methode ermöglicht es, Antworten zu generieren, die nicht nur allgemein korrekt, sondern auch im spezifischen Kontext des Unternehmens oder der Anfrage relevant sind.
- Effiziente Wissensnutzung: Die Fähigkeit, schnell auf umfangreiche Wissensdatenbanken zuzugreifen und diese effektiv zu durchsuchen, macht die Wissensverwaltung und -nutzung wesentlich effizienter.
Indem RAG-Systeme Prompts mit internem Wissen anreichern, schlagen sie eine Brücke zwischen dem umfangreichen, aber oft ungenutzten Wissen innerhalb von Organisationen und den täglichen Informationsbedürfnissen der Benutzer. Dieser Ansatz eröffnet neue Möglichkeiten für Unternehmen, ihr internes Wissen voll auszuschöpfen und den Informationszugang für Mitarbeiter und Kunden gleichermaßen zu revolutionieren.
RAG-Demo mit LangChain
Das LangChain Framework bietet eine umfassende Lösung für die Entwicklung und Implementierung von RAG-Systemen. Es handelt sich um ein Toolkit, das speziell darauf ausgelegt ist, die Integration von LLMs mit verschiedenen Datenquellen und Retrieval-Methoden zu erleichtern. Durch die Verwendung von LangChain können Entwickler maßgeschneiderte RAG-Systeme erstellen, die auf die spezifischen Bedürfnisse ihres Unternehmens oder ihrer Anwendung zugeschnitten sind. Hier ist ein simples Python-Skript, das als Grundlage dafür dienen kann, ein RAG-System mit dem LangChain Framework zu realisieren.Um das Skript selbst auszuführen, lege eine Datei namens my_document.pdf in das selbe Verzeichnis wie das Python Skript, installiere die notwendigen Bibliotheken mit pip install -r requirements.txt und starte das Skript mit python simple-rag-demo.py. Bedenke, dass du dafür Python auf deinem Computer installiert haben musst.
Datenschutz und Hosting-Problematik
Ein kritischer Punkt ist, dass OpenAI seine Dienste derzeit ausschließlich in den USA hostet. Dies stellt europäische Unternehmen vor die Herausforderung, die strengen Datenschutzvorschriften der Europäischen Union, insbesondere die Datenschutz-Grundverordnung (DSGVO), einzuhalten. Die Übertragung und Speicherung personenbezogener Daten außerhalb der EU, besonders in Ländern, deren Datenschutzniveau nicht als gleichwertig anerkannt wird, erfordert zusätzliche rechtliche und technische Maßnahmen. Dies kann den Einsatz von OpenAI-Lösungen für europäische Unternehmen komplizieren, da sie sicherstellen müssen, dass ihre Datenverarbeitungspraktiken konform mit den lokalen Datenschutzgesetzen sind.
Selbst gehostete Open Source Alternativen
Als Antwort auf diese Problematik gewinnen selbst gehostete Open Source Large Language Models und Vektordatenbanken an Bedeutung. Diese Alternativen ermöglichen es Unternehmen, die volle Kontrolle über ihre Daten und die Infrastruktur zu behalten. Indem sie ihre eigenen Instanzen von LLMs und Vektordatenbanken auf Servern hosten, die den lokalen Datenschutzgesetzen entsprechen, können Unternehmen sicherstellen, dass ihre Datenverarbeitung die Datenschutzanforderungen erfüllt. Zudem bieten selbst gehostete Lösungen eine größere Flexibilität in Bezug auf Anpassung und Integration in bestehende Systeme.
Vorteile selbst gehosteter Lösungen
- Datenschutzkonformität: Unternehmen können die Einhaltung der DSGVO und anderer lokaler Datenschutzgesetze sicherstellen, indem sie die volle Kontrolle über die Datenhaltung und -verarbeitung behalten.
- Datensicherheit: Selbst gehostete Lösungen ermöglichen es Unternehmen, ihre eigenen Sicherheitsprotokolle zu implementieren, um den Schutz sensibler Daten zu gewährleisten.
- Anpassungsfähigkeit: Open Source Modelle bieten die Möglichkeit zur Anpassung, was Unternehmen erlaubt, die Modelle spezifisch auf ihre Bedürfnisse zuzuschneiden.
Abschließender Ausblick
Die Wahl zwischen der Nutzung von Cloud-basierten Diensten wie OpenAI und selbst gehosteten Open Source Lösungen hängt von mehreren Faktoren ab, einschließlich der spezifischen Datenschutzanforderungen, der technischen Kapazitäten und der strategischen Ziele eines Unternehmens. Während Cloud-Dienste für ihre Bequemlichkeit und Skalierbarkeit geschätzt werden, bieten selbst gehostete Lösungen eine wertvolle Alternative für Unternehmen, die höchsten Wert auf Datenschutz, Sicherheit und Anpassungsfähigkeit legen.In einer Zeit, in der der Datenschutz zunehmend in den Fokus rückt, ist es entscheidend, dass Unternehmen die verschiedenen Optionen sorgfältig abwägen und Lösungen wählen, die sowohl ihre operativen Anforderungen erfüllen als auch ihre Daten schützen. Die Entwicklung und Verbreitung von Open Source LLMs und Vektordatenbanken spielen dabei eine zentrale Rolle, indem sie den Weg für datenschutzkonforme, flexible und leistungsstarke Anwendungen der künstlichen Intelligenz ebnen.
.jpg)
.jpg)
.jpg)